In 6.0.3, the Engineering Lifecycle Management (ELM) solution began publishing Java Management Extensions (JMX) MBeans for managing and monitoring ELM applications. In 6.0.5, the Lifecycle Query Engine (LQE) application began publishing its own MBeans. The recommended mechanism for collecting and viewing any of these MBeans is through an enterprise monitoring solution. However, often while getting familiar with MBean content while building your monitoring dashboards, you just want to browse the MBeans from a running system without having to first ingest it into a monitoring tool.
The typical method for doing so is via repodebug. This is described in the Troubleshooting section at the bottom of CLM Monitoring.
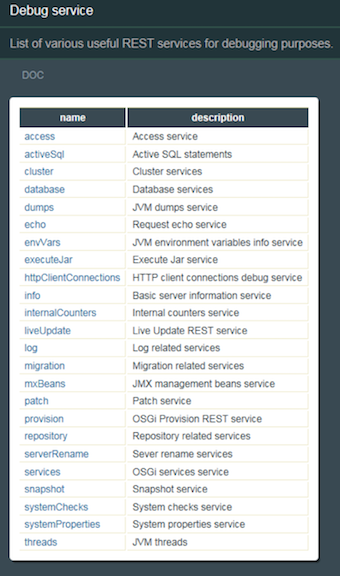
For the LQE application, repodebug can be used to view its MBeans if there are other MBean providers running on the same server. This is not typically the case as we recommend LQE be run on its own server. Fortunately, other options exist such as Jconsole and VisualVM. This post will describe how I used Jconsole to view the LQE MBeans from ELM 7.0 running on Windows and with Websphere Liberty as the application server. The instructions may differ slightly when used with traditional Websphere or another supported operating system.
The base ELM install does not include Jconsole. It is generally part of any Java SDK install. I downloaded an IBM Java SDK to the LQE server. After expanding the zip file, navigate to the bin directory and run the jconsole.exe.
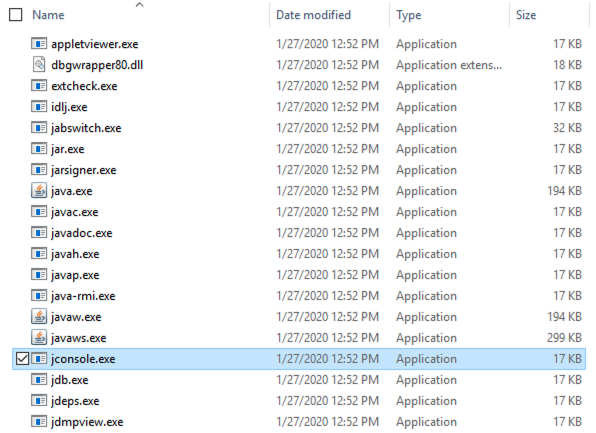
When the connection dialog appears, select Local Process and the ws-server.jar process then click Connect. I have not tried running this remotely using the Remote Process selection.
The main console window appears.
Select the MBeans tab.
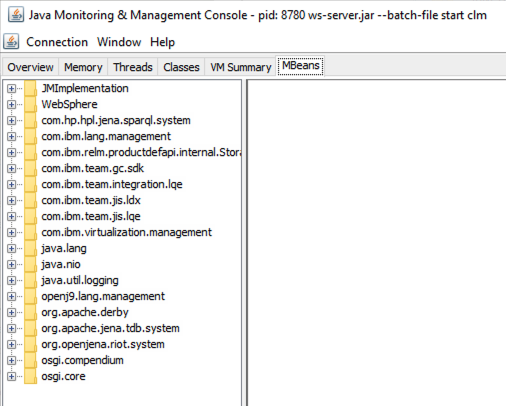
Here you see several domains of MBeans, only a two of which apply to LQE: com.ibm.team.integration.lqe and com.ibm.team.jis.lqe. You’ll see there are also domains related to GC and LDX as I am running this on a server with multiple applications (despite my earlier comments regarding running LQE on its own server, but this is a test system). Note unlike many of our application MBeans, which need enabling to have them published, the LQE MBeans are collected and published automatically.
As described in Monitoring the performance of Lifecycle Query Engine using MBeans, there are MBeans that provide performance and activity metrics for the processing of the Tracked Resource Set (TRS) feeds. You can view these by navigating to com.ibm.team.integration.lqe > IndexingAgentMetrics then expanding one of the TRS feeds down to Attributes as shown below.
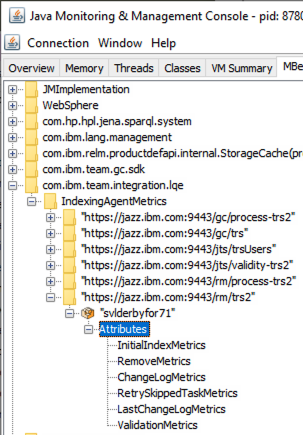
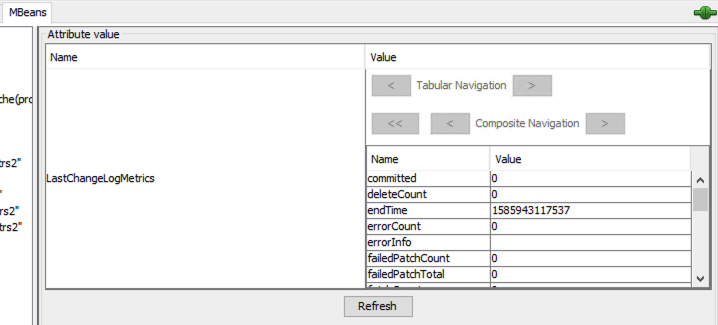
Select LastChangeLogMetrics in the Attributes list then double click javax.management.openbean.CompositDataSupport on the right panel under Value.

Now you can view and scroll through all the attributes for the LastChangeLogMetrics MBean
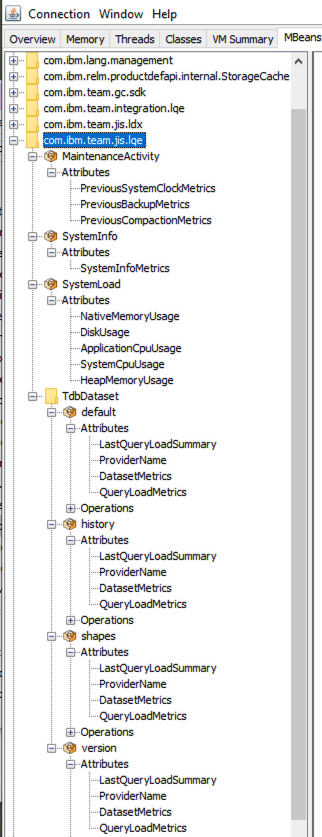
Similarly, you can navigate through the list of MBeans in the com.ibm.team.jis.lqe domain.
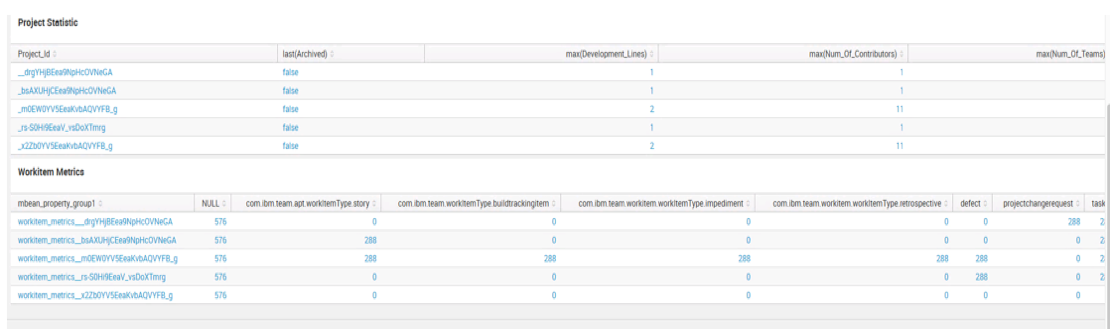
Viewing the MBeans this way only gives you the current snapshot of what has been published. You’ll get more value using an enterprise monitoring tool where the MBean data can be collected over time in a data warehouse from which dashboards showing trends and correlated with other MBean data can be created.


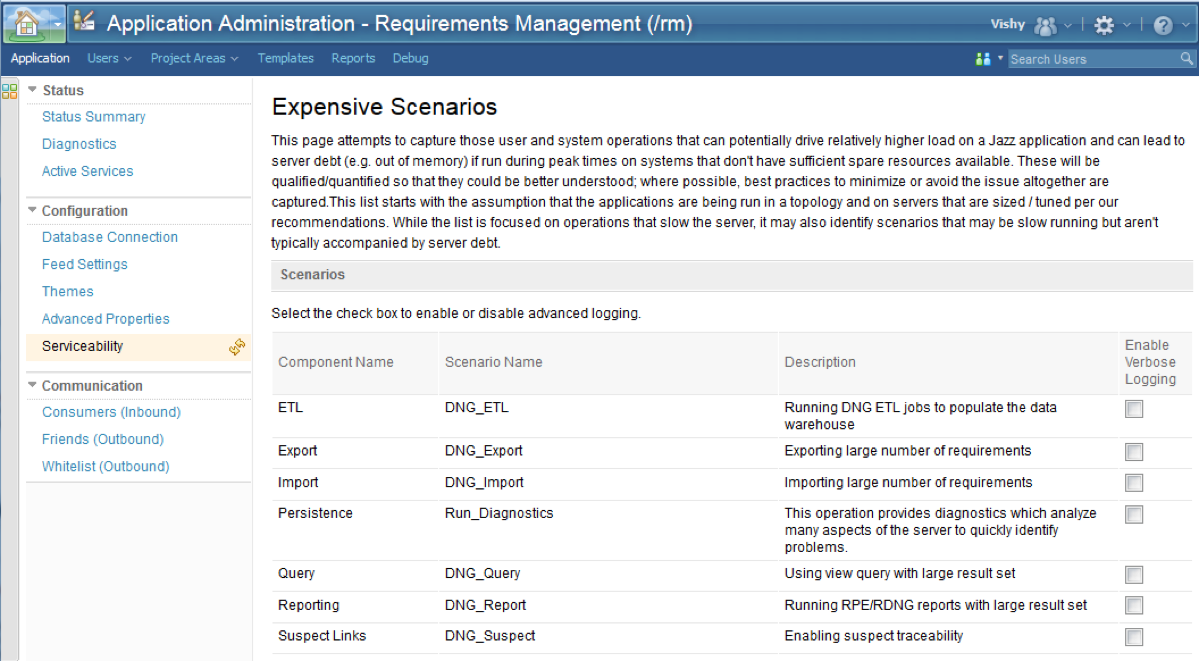
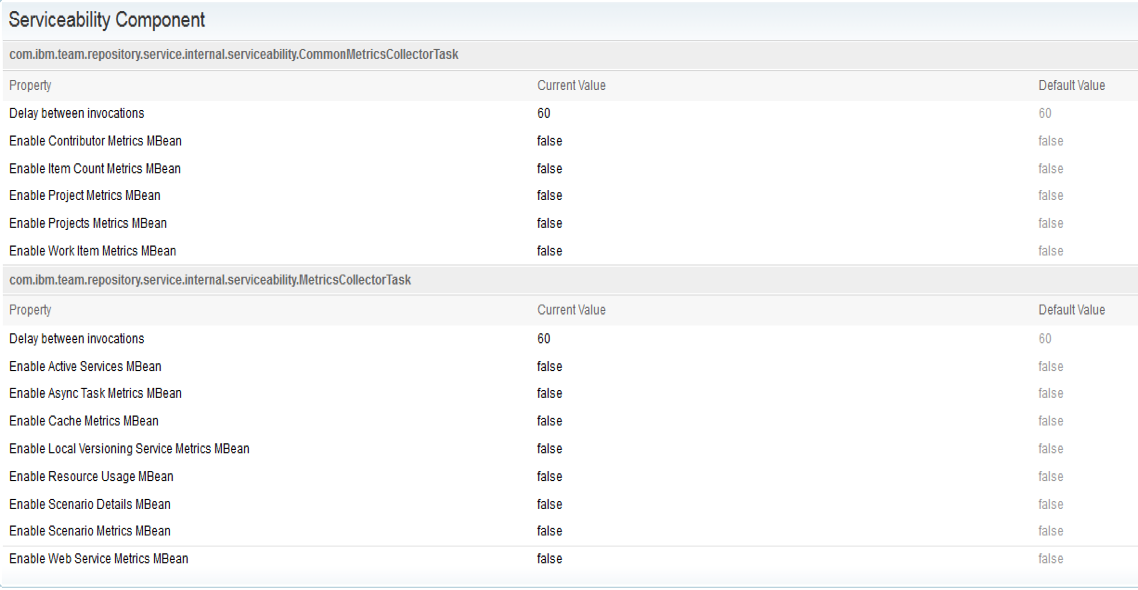
 To get additional details when the scenario occurs and to aid in understanding its characteristics, advanced (verbose) logging can be enabled. This can be done from the Serviceability page of an application’s admin UI. Note the enabling verbose logging does not require a server restart.
To get additional details when the scenario occurs and to aid in understanding its characteristics, advanced (verbose) logging can be enabled. This can be done from the Serviceability page of an application’s admin UI. Note the enabling verbose logging does not require a server restart.